مبانی پردازش زبان طبیعی(NLP)- چهار
دوشنبه ۲۸ تیر ۱۴۰۰
مهندسی ویژگی (Feature Engineering)
خلاصه ای از جلسات قبل: تا الان یاد گرفتیم که چطوری دیتایی که یکم نامنظمه رو بخونیم. و با حذف علائم نگارشی و کلمات توقف و جدا کردن کلمات و همچنین استفاده از استمر دیتا رو تمیز کردیم. و در آخر برداری کردن دیتا رو با چند روش مختلف برای ساخت مدل یاد گرفتیم. پس ما الان یک دیتا و لیبل زده تمیز داریم که برای استفاده در مدل آماده است.
حالا یک قدم تا ایجاد مدل واقعی فاصله داریم و اون مهندسی ویژگیه.
مهندسی ویژگی چیه؟
مهندسی ویژگی یعنی یک سری ویژگی جدید بسازیم یا از ویژگی های موجود رو طوری تغییر بدیم تا بیشترین بهره وری رو از دیتا داشته باشیم.
الان که دیتا رو برداری کردیم با توجه به روشی که استفاده کردیم از یه سری ویژگی های محدود استفاده می کنه. در اینجا ویژگی هایی که می تونیم اضافه کنیم مثلا می تونه موارد زیر باشه:
- طول پیام. شاید مثلا پیام های اسپم طولانی تر باشند.
- درصد علائم نگارشی استفاده شده در پیام. شاید در پیام های واقعی خیلی از علئم نگارشی استفاده نشه.
- تعداد کارکترهای با حروف بزرگ. چوت این دیتاست انگلیسیه می تونیم همچین ویژگی ای داشته باشیم.
این چند نمونه ویژگی ایه که در این دیتاست می تونیم برای تشخیص بهتر پیام های اسپم و غیراسپم استفاده کنیم.
و برای تغییر شکل (transform) ویژگی های موجود در دیتا یکسری کارها و فرمول های رایج وجود داره، مثلا:
- تغییرات توانی (Power transformation): مثل محاسبه جذر یا توان دو دیتا و …
- استانداردسازی دیتا. بعضی مدل ها زمانی بهتر کار می کنند که تمام ویژگی هاشون در یک مقیاس (scale) باشه.
برای نمونه دیگری از تبدیل به مثال زیر دقت کنید:
تصویر سمت چپ یک نمونه دیتاست رو نشون می ده که داده ها پراکنده هستند و نمی شه ارتباط درستی پیدا کرد. در همچین مواردی که یک دنباله طولانی داریم از لگاریتم استفاده می کنیم.
در حالت کلی برای ایجاد ویژگی باید مسئله رو به درستی درک کنیم و دید خوبی نسبت بهش پیدا کنیم، و همچنین باید خلاقیت داشته باشیم و تو ذهنمون تصور کنیم که از چی می خوایم به چی برسیم و برای رسیدن به اون هدف چه ویژگی هایی نیاز داریم. مثلا در تشخیص پیام اسپم و غیراسپم پیدا کردن تعداد حروف a در پیام ها ممکنه کمک چندانی به حل مسئله نکنه و ویژگی مناسبی برای این مسئله نباشه ولی مثلا تعداد علائم نگارشی استفاده شده یا طول پیام به نظر مفیدتر می آد.
تولید ویژگی
بریم سراغ کد:
اینجا می خوایم دو تا ویژگی طول پیام و درصد علائم نگارشی در پیام رو ایجاد کنیم.
بعد از خوندن دیتای خام می آییم ویژگی طول پیام رو اول می سازیم:
datsset['body_len'] = dataset['body'].apply(lambda x: len(x) - x.count(" "))
خب len(x) به ما طول پیام رو می ده ولی نکته ای که هست اینه که کاراکتر فاصله هم شمرده می شه. مثلا ممکنه یک پیام به طول 10، نه کاراکتر فاصله داشته باشه و این نباید برابر باشه با پیامی که ده کاراکتر غیرفاصله داره. پس برای همین تعداد فاصله ها شمرده می شه و از طول کل پیام کم می شه.
یک ویژگی مفید دیگه هم درصد علائم نگارشی در پیام هاست. برای محاسبه ش باید یک تابع بنویسیم:
def count_punctuation(text):
count = sum([1 for char in text if char in string.punctuation])
return round(count/(len(char) - char.count(" ")), 3) * 100
این تابع چیکار می کنه؟ اول از همه یکی یکی علائم نگارشی رو می شماره و در نهایت با تابع sum() این یک ها رو جمع می کنیم. قراره درصد علائم نگارشی استفاده شده در پیام رو برگردونه. مقدار count تعداد علائم نگارشی یک پیامه. برای محاسبه درصد باید بیاییم این مقدار رو تقسیم بر کل کاراکترهای غیرفاصله پیام کنیم. بعد چون یک مقدار اعشاری برمی گردونه برای اینکه عدد خیلی طولانی نباشه رند می کنیم عدد رو تا سه رقم اعشار نشون بده و در نهایت در 100 ضرب می کنیم تا از حالت اعشار خارج شه.
کد کامل رو اینجا می تونید مشاهده کنید.
ارزیابی ویژگی
حالا باید بررسی کنیم که این ویژگی ها برای این دیتاست مناسبن یا نه؟ که آیا می تونیم برای استخراج اطلاعات بهتر ازشون استفاده کنیم یا نه؟ از کتابخونه matplotlib برای رسم نمودار و هیستوگرام استفاده می کنیم. از تابع hist() در مجموعه توابع pyplot استفاده می کنیم:
ویژگی اولی که ساختیم طول پیام بود. حدس زدیم که احتمالا پیام های اسپم طولانی ترند. بریم ببینیم این حدس درسته یا نه؟
bins = np.linspace(0, 200, 40)
pyplot.hist(dataset[dataset['label'] == 'spam']['body_len'], bins, alpha=0.5, density=True, label='spam')
محدوده و تعداد استوانه ها رو با bin مشخص می کنیم و مقادیری که می بینید به این ترتیبه: bins = np.linspace(min_boundary, max_boundary, n_bins).
ممکنه در کدهای قدیمی تر پارامتر normed=True رو ببینید که این معادل پارامتر density است که اینجا استفاده کردیم در نسخه های جدیدتر پایتون از این پارامتر استفاده می شه.
همین خط کد رو باید یرای پیام های غیراسپم هم بنویسیم تا بتونیم مقایسه کنیم.
بعد از گرفتن خروجی می بینیم که پیش بینی مون درست بوده و پیام های اسپم بسیار طولانی تر از پیام های غیراسپمن. پس این ویژگی که ایجاد کردیم مناسب و مفیده.
برای تست ویژگی بعدی همین خط کد رو داریم فقط به جای [body_len] باید [punct%] رو بذاریم تا ببینیم طبق حدسمون پیام های اسپم بیشتر از غیراسپما علائم نگارشی دارند؟
bins = np.linspace(0, 50, 40)
pyplot.hist(dataset[dataset['label'] == 'spam']['punct%'], bins, alpha=0.5, density=True, label='spam')
و بعد از اجرای کد می بینیم که تفاوت چشمگیری در استفاده از علائم نگارشی بین پیام های اسپم و غیراسپم وجود نداره. و همونطور که در این توزیع دیده می شه یه دنباله ای در پیام های غیراسپم ایجاد شده که احتمالا باید از تبدیل (transformation) استفاده کنیم تا بهتر بتونیم تصمیم بگیریم.
تبدیل (Transformation)
در این بخش می خوایم بررسی کنیم که دو تا ویژگی ای که ایجاد کردیم نیاز به تبدیل دارند یا نه.
اولین کاری که باید انجام بدیم اینه که توزیع کاملشون رو رسم کنیم و بعد طبق اون تصمیم بگیریم. مواردی که نشون می ده تبدیل نیازه یا نه، عدم تقارن شدید، دنباله طولانی و outlierها (یعنی اون نقاطی که خیلی از توزیع اصلی دورافتادن).
طول پیام
برای شروع bins رو مثل قبل تعریف می کنیم، از صفر شروع شه تا 200 بره و 40 تا bin تولید شه:
bins = np.linspace(0, 200, 40)
pyplot.hist(dataset['body_len'], bins)
نیازی به پارامترای دیگه نیست چون می خوایم توزیع کلی طول پیام ها رو ببینیم، بدون توجه به لیبلشون.
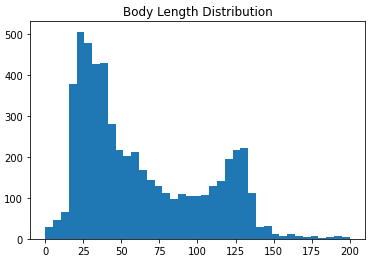
همونطور که قبلا دیدیم طول پیام های اسپم بیشتر از غیراسپم ها بود پس این توزیع درست و با معنیه. پس این ویژگی نیازی به تبدیل نداره.
درصد پیام های نگارشی
برای بررسی ویژگی بعد 200 رو به 50 تغییر می دیم یعنی متن های تا 50 تا علائم نگارشی رو بررسی کنه.
bins = np.linspace(0, 50, 40)
pyplot.hist(dataset['punct%'], bins)
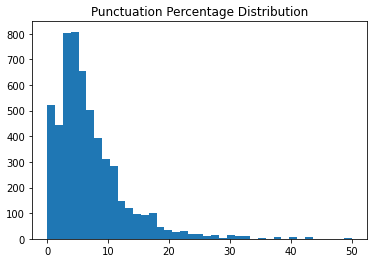
این توزیع رو همونطور که می بینید تقارن نداره مقدار زیادی از دیتا نزدیک صفر جمع شده و همینطور یک دنباله طول و دراز هم تشکیل شده که نشون می ده نیاز به تبدیل داره.
حالا که ویژگی هایی که نیاز به تبدیل دارند رو مشخص کردیم، باید تبدیل رو شروع کنیم.
تبدیل (Transformation) فرایندیه که هر داده رو در یک ستون مشخص به صورت سیستماتیک تغییر می ده (مثلا محاسبه جذر یا توان دوم هر داده) تا دیتا رو برای استفاده بهتر مدل از اون، پاکسازی کنه.
مجموعه تبدیلی که اینجا استفاده می کنیم بسیار رایجه و Box-Cox Power Transformations نام داره. فرم پایه این تبدیلات y به توان x است. جدول زیر این تبدیل رو برای بازه [-2,2] نمایش می ده:
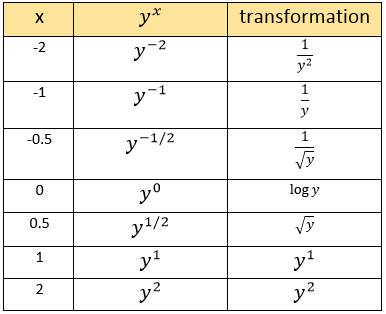
حالا اگر فرض کنیم 50 درصد یک متن علائم نگارشیه، در جدول بالا x = 50 می شه.
فرایند تبدیل
1- مشخص کردن بازه توانی
2- اعمال هر تبدیل را به هر مقدار ویژگی انتخاب شده
3- استفاده از معیارهایی برای تشخیص تبدیلی که بهترین توزیع را تولید می کند
بعد از بررسی ویژگی هایی که ایجاد کردیم دیدیم که ویژگی علائم نگارشی نیاز به تبدیل داره. کد اعمال تبدیل رو به این صورت می نویسیم:
for i in range(1, 6):
pyplot.hist((dataset['punct%'])** (1/i), bins=40)
pyplot.title('transformation: 1/{}'.format(str(i)))
برای مطالعه بیشتر درباره تبدیل و مهندسی ویژگی این مقاله رو می تونید مطالعه کنید.
nlp اموزش سورس