مبانی پردازش زبان طبیعی(NLP)- سه
پنجشنبه ۲۴ تیر ۱۴۰۰
در این قسمت در مورد برداری کردن دیتا صحبت می کنیم.
تا اینجا دیتا رو خوندیم و تا حدودی نرمالیزه کردیم. الان پایتون دیتا رو فقط یک سری رشته کاراکتر می بینه. حالا برای اینکه مدل ماشین لرنینگ و پایتون این دیتا رو درک کنه باید دیتا برداری بشه. برداری کردن یعنی چی؟ یعنی متن به عددصحیح تبدیل شه و یک بردار ویژگی ساخته شه.
حالا بردار ویژگی در اینجا یعنی متن هر پیام رو بگیریم و به یک بردارعددی تبدیل کنیم که نمایش دهنده متن اون پیام باشه.
چطوری این کار رو انجام می دیم؟ در ادامه درباره این مورد صحبت می کنیم.
چندین روش برای برداری کردن ویژگی ها وجود داره که در ادامه سه روش رایج رو بررسی می کنیم.
روش اول: بردار تعداد (Count Vectorization)
در این روش هر پیام گرفته می شه و هر کلمه به عنوان یک ویژگی در نظر گرفته می شه و بعد تعداد تکرار هر کلمه در اون پیام ثبت می شه. در نهایت یک ماتریسی داریم که هر سطر مربوط به یک پیام و هر ستون نمایش دهنده یک کلمه است. و در نهایت پایتون با بررسی این ماتریس یک ارتباطی بین کلمات موجود در پیام و لیبل اون پیام پیدا می کنه تا در آینده که بهش پیام های بدون لیبل بدیم بتونه به درسی برچسب گذاری کنه.
برای درک بهتر این فرایند به عکس زیر دقت کنید:
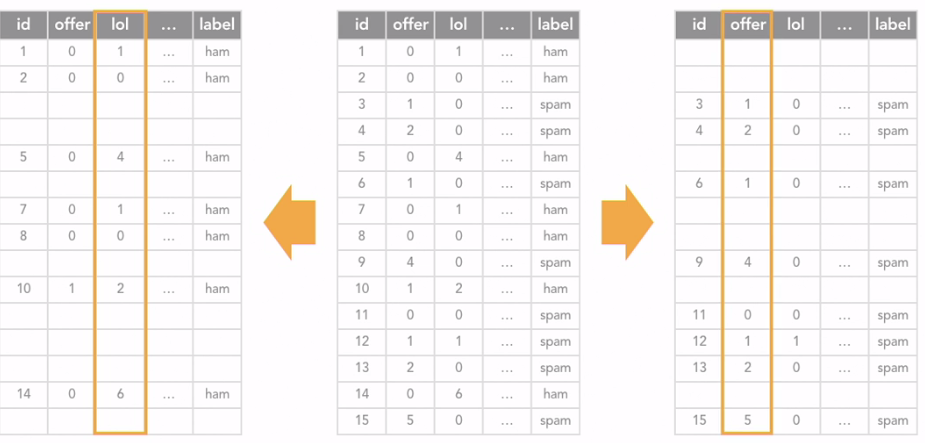
دراین تصویر فقط دو رشته offer و lol از لیست کلمات پیام ها انتخاب شده و تعداد تکرارشون محاسبه شده. همونطور که در جدول سمت چپ و راست می بینید پیام هایی که برچسب غیر اسپم دارند در آن ها رشته lol وجود داشته و تکرار شده ولی شامل رشته offer نیستند و برعکس پیام های اسپم اکثرا رشته offer رو شامل می شن.
این یک مثال بسیار ساده برای درک فرایند و مفهوم بردار تعداد است.
حالا در عمل این روش رو پیاده می کنیم:
import pandas as pd
import re
import string
import nltk
pd.set_option('display.max_colwidth', 100)
dataset = pd.read_csv('SMSSpamCollection.tsv', sep='\t')
dataset.columns = ['label', 'body']
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words('english')
ps = nltk.PorterStemmer()
def clean_text(text):
text = "".join([word.lower() for word in text if word not in string.punctuation])
tokens = re.split('\W+', text)
text = [ps.stem(word) for word in tokens if word not in stopwords]
return text
بعد از خوندن و پاکسازی دیتا، سراغ برداری کردن می ریم.
from sklearn.feature_extraction import CountVectorizer
count_vect = CountVectorizer(analyzer=func_name)
X_counts = count_vect.fit_transform(dataset['body'])
حالا می تونیم با استفاده از X_counts.shape تعداد پیام ها و تعداد رشته های منحصر بفرد در این پیام ها رو ببینیم. در این دیتاست 5567 پیام و 8104 رشته منحصر بفرد داریم که همون ویژگی های ما هستند. این اعداد تعداد سطرو و ستون های ماتریس رو نمایش می ده.
و count_vect.get_feature_names() رشته های منحصربفرد رو نمایش می ده.
تابع هایپرپارامترهای دیگه ای هم داره که اینجا می تونید دربارشون بخونید.
حالا در اینجا برای یادگیری 20 پیام اول رو برداری می کنیم:
sample = dataset[0:20]
count_vect_sample = CountVectorizer(analyzer=clean_text)
X_counts_sample = count_vect_sample.fit_transform(dataset['body'])
و الان وقتی سایز دیتای نمونه رو ببینیم 192 رشته منحصربفرد داریم. خروجی و کد کامل این بخش رو اینجا می تونید ببینید.
روش دوم: بردار N-Grams (N-gram vectorizing)
این روش هم تا حدود زیادی مشابه روش قبلیه و ساختار کدش مشابه اونه. در اینجا هم هر سطر پیام ها هستند ولی هر ستون به جای نمایش یک رشته، ترکیب nتایی از رشته هاست. برای درک بهتر تصویر زیر رو ببینید:
مثل مرحله قبل دیتا رو می خونیم و بعد باید تابعی بنویسیم که مراحل پاکسازی رو انجام بده. بخش قبل یک لیستی از توکن رو می دادیم به vectorizer اما الان چون می خواد ترکیبی از کلمه ها رو بسازه باید ورودی بهش یک رشته بدیم. پس در آخر باید توکن ها رو مثل یک جمله کنار هم دیگه قرار بدیم و این کار رو با تابع join() انجام می دیم:
def clean_text(text):
text = "".join([word.lower() for word in text if word not in string.punctuation])
tokens = re.split('\W+', text)
text = " ".join([ps.stem(word) for word in tokens if word not in stopwords])
return text
اگر یادتون باشه خط اول کاراکترها رو یکی یکی بررسی می کرد برای پیدا کردن علائم نگارشی و در اخر با join() این کاراکترها رو بهم متصل کردیم. در join() دومی قرار کلمه ها کنار هم بیان تا جمله بسازن پس باید یک فاصله بین هر کلمه باشه.
در اینجا هم از CountVectorizer استفاده می کنیم:
ngram_vect = CountVectorizer(ngram_range=(2,2))
X_counts = ngram_vect.fit_transform(dataset['cleaned_text'])
در ngram_range مشخص می کنیم که ترکیب چندتایی از کلمه ها بسازه. مثلا (1,3) یعنی همه ترکیبهای یکی، دوتایی و سه تایی.
همونطور که مشاهده می کنید تعداد فیچرها اینجا خیلی زیاد می شه. نکته ای که باید توجه کنیم اینه که چه زمانی از هر کدوم از این روش ها استفاده کنیم. با توجه به مسئله ممکنه یکی از این روش ها نتیجه بهتری بده. لزوما نمی شه گفت یکی از این روش ها بهتر از دیگری است.
کدهای این بخش در اینجا قابل مشاهده است.
روش سوم: TE-IDF (Term Frequency- Inverse Document Frequenct)
در این روش هم یک ماتریس ایجاد می شه که سطرها پیام ها هستند و هر ستون یک کلمه رو مشخص می کنه. اما سلول های این ماتریس دیگه تعداد تکرار کلمه رو نشون نمی ده بلکه وزن اون کلمه رو نشون می ده، تا اهمیت هر کلمه رو در اون پیام مشخص کنه.
فرمول زیر برای محاسبه این وزنه:
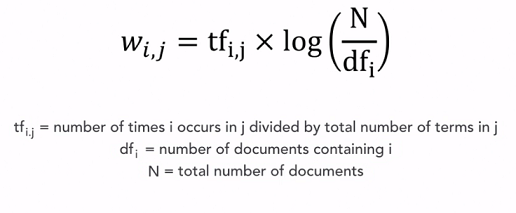
بریم ببینیم هر کدوم از این عبارات در فرمول چیو مشخص می کنه و چطوری محاسبه می شه:
عبارت tf تعداد تکرار یک کلمه در یک جمله تقسیم بر تعداد کل کلمات اون جمله.
مثلا در جمله “امروز هوا گرم است” اگر کلمه “گرم” رو در نظر بگیریم، مقدار tf می شه: 1/4 یا 0.25
قسمت دوم این فرمول مشخص می کنه که هر کلمه چند بار تو کل جملات (پیام ها) تکرار شده. در همین مثال اگر متن ما شامل 20 جمله باشه و کلمه گرم فقط یک بار تکرار شده باشه، نتیجه می شه:
N = 20, df = 1 >>>> log(N/df) = log(20/1) = 1.301
مبنای لگاریتم هم 10 است.
و درنهایت:
0.25 * 1.301 = 0.325
هر چقدر مقدار داخل لگاریتم بزرگتر باشه، لگاریتم اون مقدارم بزرگتر می شه. مثلا فرض کنید تعداد کل جملات 40 باشه مقدار لگاریتم می شه 1.6 یعنی بیشتر از مقدار قبل. پس طبق این فرمول هر چقدر یک کلمه در متن کمتر تکرار شده باشه، عددی که تولید می شه بزرگتره.
و اگر یک کلمه در یک جمله خیلی تکرار شده باشه ولی در کل متن خیلی کم باشه، مقدار نهایی عدد بزرگی می شه.
به طور خلاصه این روش کمک می کنه کلمات مهم ولی نادر رو در متن پیدا کنید.
مثل روش های قبل دیتا رو می خونیم و یک تابع برای پاکسازی دیتا می نویسیم. این تابع رو مثل روش اول می نویسیم:
def clean_text(text):
text = "".join([word.lower() for word in text if word not in string.punctuation])
tokens = re.split('\W+', text)
text = [ps.stem(word) for word in tokens if word not in stopwords]
return text
و سپس وکتورایز tf-idf رو می سازیم:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(analyzer=clean_text)
X_tfidf = tfidf_vect.fit_transform(dataset['body'])
برای اینکه یه دیدی بگیریم بهتره یه بخشش کوچکی از دیتا رو انتخاب کنیم و دیتافریم ماتریس رو بسازیم تا خروجی رو ببینیم. برای ایجاد ماتریس از تابع toarray() و دیتافریم پانداس استفاده می کنیم:
X_tfidf_df = pd.DataFrame(X_tfidf_sample.toarray())
کد کامل اینجا قرار داره.
nlp اموزش سورس