مبانی پردازش زبان طبیعی(NLP)- یک
شنبه ۱۹ تیر ۱۴۰۰
این پست رو با یک نقل قول شروع می کنم:
"Motivation often comes after starting, not before. Action produces momentum."
تعاریف متفاوتی برای پردازش زبان طبیعی وجود داره ولی شاید کامل ترینش این باشه:
پردازش زبان طبیعی شاخه ای از دانشه که بر روی توانایی کامپیوتر برای درک، تحلیل، تغییر و احتمالا تولید زبان انسان متمرکز است.
در چند سری پست آینده می خوام یک سری مبانی برنامه نویسی مربوط به پردازش زبان طبیعی رو توضیح بدم، کدها هم در این ریپو قرار دارند. در این آموزش فرض شده که شما با مبانی پایتون یا حداقل برنامه نویسی آشنا هستید چون اینجا مبانی، مثل استفاده از لیست و دیگر نوع داده ها آموزش داده نمی شه.
زبانی که در این سری استفاده می شه پایتونه، پس نیازه که پایتون رو نصب کنید. برای محیط برنامه نویسی هم می تونید از پایچارم یا ژوپیتر استفاده کنید. برای استفاده از ژوپیتر باید آناکوندا رو نصب کنید. لینک سایت اصلی این برنامه ها رو هم قرار دادم که برای دانلود می تونید استفاده کنید. حتما دقت کنید که هر برنامه رو برای سیستم عامل خودتون دانلود کنید (خود این سایت ها به صورت خودکار سیستم عامل رو شناسایی می کنند).
بخش اول: خواندن فایل
خب شروع کنیم. تو این قسمت قراره یک فایل متنی رو بخونیم و یک سری مرتب سازی ها روش انجام بدیم. اول یک با دیتاست بازی می کنیم تا یکسری اطلاعات از دیتاست دستمون بیاد و بعد یک روش ساده برای خوندن این دیتاست معرفی می کنیم.
فایلی که استفاده می شه در ریپویی که لینکش رو بالا گذاشتم موجوده. برای خوندن فایل باید اول با استفاده از تابع open() فایل رو باز کنیم و با تابع read() فایل باز شده رو می خونیم و محتواش رو در یک متغیر به اسم raw_data می نویسیم.
raw_data = open('file_name').read()
خب حالا باید ببینیم محتوای این raw_data به چه صورته تا ببینیم نیاز به مرتب سازی داره برای پردازش های بعدی یا نه. فایل رو اگر دیده باشید داده نه ساختاریافته نیست و خیلی هم بدون ساختار نیست، اول هر خط کلمه ham یا spam داره و بعد با یه تب فاصله یک متنی جلوش نوشته شده. بریم چند خط از فایل رو ببینیم:
raw_data[0:500]
بعد از اجرای این خط 500 کاراکتر اول فایل نمایش داده می شه. همون طور که می بینید محتوای فایل یک سری رشته است که کاراکترهایی مثل \t و \n داره. اولی فاصلی ای مه باتب ایجاد شده رو نشون می ده و دومی باعث می شه بره خط بعدی.
خب ما الان می خوایم یکم داده رو مرتب کنیم، برای پردازش های بعدی. برای اینکار کاراکتر \t رو با \n جایگزین می کنیم و بعد با تابع split این رشته رو به لیست تبدیل می کنیم.
parsed_data = raw_data.replace('\t','\n').split('\n')
بریم ببینیم لیست مون چه شکلیه:
parsed_data[:5]
الان برچسب یا لیبل در خونه های با ایندکس زوج قرار داره و متن پیام در خونه های ایندکس فرد. حالا که یه نظمی تو ساختار ایجاد شده بریم هر کدوم رو تو لیست جدا بنویسیم:
label_list = parsed_data[0::2]
text_list = parsed_data[1::2]
اولی لیست رو از خونه صفر می خونه و یکی درمیون مقادیر رو می ریزه تو لیست لیبلا، یعنی همون خونه های زوج. خط دوم از خونه یک میاد یکی در میون می خونه و باعث می شه خونه های فرد رو بخونه.
می تونیم این دو لیست رو ببینیم و مطمئن شیم همونطور که می خواستیم شده. اینجا از تابع print() استفاده می کنیم چون در غیر اینصورت ژوپیتر فقط خروجی اخرین خط رو می ده.
print(label_list[:5])
print(text_list[:5])
حالا باید این دو لیست رو یه جوری با هم ترکیب کنیم تا برای تحلیل های بعدی بتونیم ازشون استفاده کنیم. برای این کار از تابع DataFrame() پانداس استفاده می کنیم و در این دیتافریم یک دیکشنری می سازیم. بعد از ایمپورت کتابخونه می تونیم از توابعش استفاده کنیم:
import pandas as pd
full_corpus = DataFrame({'label': label_list, 'body': text_list})
احتمالا بعد از اجرای این خط کد اروری مشاهده می کنید که می گه ارایه ها باید طولشون یکسان باشه. بریم طول این دو لیست رو چک کنیم:
print(len(label_list))
print(len(text_list))
همون طور که می بینید طول لیست لیبل یه دونه بیشتر از متنه. بریم چند تا خونه اخر هر دو لیست رو ببینیم چه خبره:
label_list [-5:]
text_list[-5:]
خونه اخر لیست لیبلا یه خونه خالیه. پس وقتی این لیست رو می خونیم، خونه اخر رو باید نادیده بگیریم:
full_corpus = DataFrame({'label': label_list[:-1], 'body': text_list})
ببینیم دیتافریم مون چه شکلیه:
full_corpus.head()
خب الان دیتامون یکم ساختار پیدا کرده و نسبت به اول خوانایی بهتری داره.
و اما روش ساده خوندن این دیتاست. همون اول که نگاهی به داده انداختیم و \t رو دیدیم باید متوجه شیم که این یک فایلیه که عناصرش با تب از هم جدا شدن. برای خوندن این فایل ها می تونیم از تابع read_csv استفاده کنیم، مقدار هدر رو هم در اینجا None قرار می دیم چون در فایل اصلی ردیفی برای عنوان ستون وجود نداره.
dataset = read_csv('file_name', sep="\t", header=None)
برای مشاهده هم می تونیم از تابع head() استفاده کنیم:
dataset.head()
همونطور که می بینید دیگه ردیف اولی برای عنوان ستون ها وجود نداره.
در این بخش یاد گرفتیم که یک دیتاست متنی رو چطوری بخونیم و برای تحلیل های بعدی مرتبش کنیم. کدهای بخش اول رو از اینجا می تونید ببینید.
بخش دوم: بررسی دیتاست
بخش قبل یاد گرفتیم که چطور دیتا رو به روش پیچیده بخونیم تا با یک سری از ابزارهای تغییر در متن آشنا شیم و در آخر روش ساده رو یاد گرفتیم:
dataset = read_csv('file_name', sep="\t", header=None)
حالا برای ستون ها اسم برچسب می ذاریم تا راحت بتونیم دیتا رو بررسی کنیم: dataset.columns[‘label’, ‘body’]
اول از همه بریم سایز دیتاست رو دربیاریم، ببینیم چند تا سطر و ستون داره:
print("There are {} rows and {} columns.".format(len(dataset), len(dataset.columns)))
حالا باید تعداد سطرهای اسپم و غیر اسپم رو دربیاریم:
print("Out of {} rows, {} rows are spam and {} rows are ham.".format(
len(dataset),
len(dataset[dataset['label'] == 'spam']),
len(dataset[dataset['label'] == 'hame'])
))
ممکنه بعضی ردیفا هیچ لیبلی نداشته باشه، باید تعداد اون ها رو هم پیدا کنیم:
print("Number of null in label: {}".format(dataset['label'].isnull().sum()))
print("Number of null in body: {}".format(dataset['body'].isnull().sum()))
خروجی تابع isnull() بولینه یعنی True یا False برمی گردونه. هر سطر رو بررسی می کنه اگر اون ستونی که داریم بررسی می کنیم تو اون سطر دیتا نداشته باشه True میشه و در غیراینصورت False.
وقتی بعد از isnull() تابع sum() رو میاریم یعنی تعداد کل ریف هایی که لیبل ندارن رو بده.
کدهای بخش دوم رو از اینجا می تونید ببینید.
بخش سوم: عبارات منظم
دلیل اصلی یاد گرفتن عبارات با قاعده اینه که بتونیم جمله رو tokenize کنیم یا به عبارتی کلمه های جمله رو از هم جدا کنیم که پایتون بدونه که دنبال چی بگرده. گاهی اوقات لازمه که یک الگوی خاصی از کاراکترها رو در یک رشته متن پیدا کنیم، این کار به راحتی با عبارات با قاعده قابل انجامه. البته خیلی راحتم نه :) چون روش هایی که برای تشخیص این الگوها وجود داره خیلی گسترده است ولی یک سری موارد کلی رو اگر یاد بگیرید و تمرین کنید براتون راحت می شه. از داکیومنت عبارات با قاعده در پایتون هم می تونید استفاده کنید.
در اینجا دو روش رو یاد می گیریم. برای تست این دو روش یک متن رو به سه حالت نوشتم و قراره که کلمه ها رو از هم جدا کنیم.
import re
text = "This is a made up string to test 2 different regex methods"
messy_text = "This is a made up string to test 2 different regex methods"
messy_text1 = "This-is-a''''made-up/string-+to*****test-2 >>>>>>-different.regex-methods"
برای اینکه بتونیم از این عبارات با قاعده در پایتون استفاده کنیم باید کتابخونه ش رو ایمپورت کنیم.
کلمات جمله اول با فاصله از هم جدا شدند پس یه الگو به دست اومد، می تونیم هر جا کاراکتر فاصله بود تشخیص بدیم و کلمات رو از هم جدا کنیم. با استفاده از تابع split() و ‘\s’ به کوچک و بزرگ بودن حروف دقت کنید، چون هر کدوم معنی خاصی دارند. در اینجا حرف کوچک s یعنی از نقاطی که کاراکتر فاصله وجود داره کلمات رو جدا کن.
re.split('\s', 'text')
اگر همین کد رو روی متن دوم اجرا کنیم جوابی که می خوایم رو نمی گیریم، چون بیشتر از یک کاراکتر فاصله بین بعضی کلمات وجود داره. پس از ‘\s+’ استفاده می کنیم. این یعنی یک فاصله یا بیشتر اگر بین کلمات بود حذف کن.
re.split('\s+', 'messy_text')
برای متن سوم هیچ کدوم از راه حلای بالا جواب نمی ده. و باید از راه دیگه ای بریم. اینجا به غیر از کاراکتر فاصله، کاراکترهای دیگه ای هم وجود داره. پس می تونیم بیاییم بگیم هر کاراکتر غیر کلمه ای رو حذف کن. و علامت + رو هم می ذاریم چون کاراکترهای غیرکلمه بیشتر از یکبار تکرار شدن بین هر کلمه.
re.split('\W+', 'messy_text1')
کاری که تا الان انجام می دادیم این بود که بیاییم هر چی غیر از کلمه است رو جدا می کردیم تا کلمه ها جدا شن. یه راه دیگه برای جداسازی کلمات اینه که بیاییم مستقیم کلمه ها رو پیدا کنیم. برای این کار از تابع findall() استفاده می کنیم.
re.findall('\S+', text)
در کد بالا از حرف بزرگ S استفاده کردیم. گفتیم هر چی غیر کاراکتر فاصله. که این روش دوباره روی متن سوم جواب نمیده. که می تونیم از روش زیر به جای این استفاده کنیم.
re.findall('\w+', 'messy_text1')
حرف کوچک w رو اینجا استفاده کردیم. یعنی کاراکترهای کلمه رو جدا کن.
کدهای بخش سوم اینجا قرار دارند.
یک کار دیگه ای که می شه با این عبارات با قاعده انجام داد اینه که کلماتی که املاشون اشتباه نوشته شده در یک متن رو پیدا کرد و با مقدار درستش جایگزین کرد. مثال این مورد رو می تونید در اینجا مشاهده کنید.
بخش چهارم: پیش پردازش (پاکسازی) داده
برای اینکه داده آماده بررسی و تحلیل بشه باید یکسری مراحل به عنوان پیش پردازش روش انجام بشه تا مواردی که اضافه است حذف بشه. این مراحل شامل حذف علائم نگارشی، تقسیم جمله به کلمه ها متشکل، حذف کلماتی که معنی خاصی ندارندو حذف مشتقات کلمات می شود.
بریم پنج سطر اول دیتا رو دوباره ببینیم:
import pandas as pd
pd.set_option('display.max_colwidth', 100)
dataset = pd.read_csv('file_name', sep='\t', header=None)
dataset.columns = ['label', 'body']
dataset.head()
خط دوم set_option('display.max_colwidth', 100) تعداد کاراکترهایی که نمایش داده می شه رو مشخص می کنه.
الان دیتا به این صورته:

فایل دیتاست بعد از پاکسازی هم در این فولدر وجود داره و قراره دیتا به این صورت دربیاد:
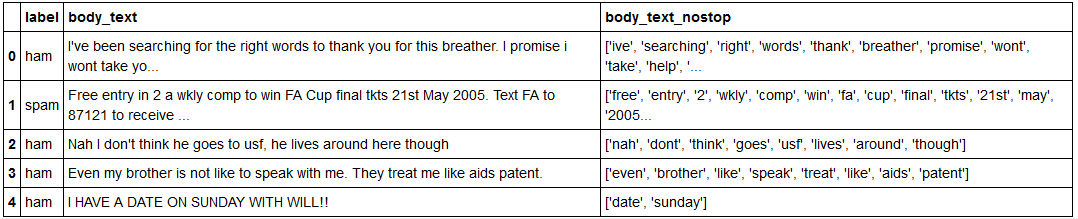
حذف علائم نگارشی
علائم نگارشی در کتابخونه string قرار دارند. باید یک تابع بنویسیم که این علائم نگارشی رو از متن پیام در دیتا حذف کنه. و متن بدون علائم نگارشی بده.
def remove_punct(text):
text_nopunct = [char for char in text if char not in string.punctuation]
return text_nopunct
dataset['body_nopunct'] = dataset['body'].apply(lambda x: remove_punct(x))
در اینجا چون متن پیام رو داره کاراکتر به کاراکتر بررسی می کنه در نهایت هم کاراکتر ها رو از هم جدا می کنه و به عنوان خروجی می ده، برای اینکه به صورت کلمه خروجی بگیریم از تابع join() استفاده می کنیم.
text_nopunct = "".join([char for char in text if char not in string.punctuation])
جداسازی کلمات
import re
def tokenize(text):
tokens = re.split('\W+', text)
return tokens
dataset['body_tokenized'] = dataset['body_nopunct'].apply(lambda x: tokenize(x.lower()))
تابع lower() شاید اینجا زیاد استفاده نشه و اهمیتش مشخص نباشه ولی چون در پایتون حروف کوچک و بزرگ یکسان نیستند باید همه حروف در کلمات یک جور باشند.
حذف کلمات بدون معنی
هر زبانی یک سری کلمات داره که معنی خاصی در جمله ندارند و اگر حذف شوند جمله معنی خودش رو حفظ می کنه. مثل حروف ربط. با استفاده از کتابخانه nltk این کلمات رو از جمله حذف می کنیم:
import nltk
stopwords = nltk.corpus.stopwords.words('english')
حالا یک تابع می نویسیم که این کلمات رو حذف کنه از جملات:
def remove_stopwords(tokenized_list):
text_nostop = [word for word in tokenized_list if word not in stopwords]
return text_nostop
dataset['body_nostop'] = dataset['body_tokenized'].apply(lambda x: remove_stopwords(x))
کدهای بخش چهارم اینجا قرار دارند.
nlp اموزش سورس